Templates Included in this Article
This page updated 9 Feb 2024
This article describes several of my example Templates for Online Repository Assistant (ORA). The other example Templates can be found in the index of Example Templates. Other articles in my ORA Section cover various topics about using the software. The "How it Works" sections below include links to articles describing the ORA features used in these Templates.
The Templates described here are Library Templates. Library Templates are intended as a way to record a segment of Template code that one will use repeatedly. Instead of having to recreate the code for particular function for each new Template, we can record it once as a Library Template and then simply call it as needed in individual Text or Auto Type Templates. Creating Library Templates is described in the Template Library section of my article on Advanced Template Methods.
Templates Included in this Article |
|
| Removes the country name or abbreviation when it appears in place names | |
| Standardizes the recording of "Mc" names | |
| Colors output of a Text Template red | |
| Creates a distinctive divider to separate items in the OraPanel | |
| Determines that a place cannot be a township |
|
| Removes parts of place names that are not towns or cities | |
| Standardizes abbreviations of street suffixes like "street" and "avenue" | |
| Creates Variables populated with appropriate pronouns for narratives in Census Tags | |
For each Template there is a description of why it is used and what it does, notes on how to use it, and text of the Template itself. The text of each Template includes a comment line or lines describing what it does, another describing how to "call" the Library Template in a Text or Auto Type Template, then the actual Template code. That is followed by a detailed description of how it works so that readers can understand how to modify it if desired or how to apply the techniques in other applications.
Many of these examples include use of Transforms using Regular Expressions, which may seem complex to some readers. They are here precisely because they use Regular Expressions, as I find those cases to be prime candidates for Library Templates; once I work out a Regular Expression for a given task I make it a Library Template to save having to work it out again for another Collection. In the explanations below I try to explain how the Regular Expressions work. For more information on Regular Expresssions see my article on Using Regular Expressions In ORA.
Placing the code in these examples in a Library Template rather than directly in individual Templates not only avoids having to re-construct somewhat complex code. It also allows any additional terms or edits to the code that are found useful as additional records with different situations are encountered to be automatically applied in all Templates calling the Library Template involved.
As described in the article mentioned above, Library Templates may include one or more fields by specifying them in "call" statement in the Text or Auto Type Template. That field is represented in the Library Template by a number in braces: "{1}, {2}, {3}, etc.
Descriptions of these Templates are below:
Some Repositories are inconsistent, even in the same collection, in whether they include the country in a place name or not, and if so whether it is spelled out or various abbreviations are used. This inconsistency make writing Templates involving place names more difficult. This Library Template examines a place name and if the country name or an abbreviation for it are included removes it. The remaining part of the Text or Auto Type Template can then operate on the place name without having to account for a possible country element.
Library, intended for use with in a Text or Auto Type Template.
In a Text or Auto Type Template, call the Library Template using the "call" described in the second Comment Line, substituting the actual name of the field containing the place value for "place_fieldname." Place the call statement in the place in the Template where output of the place name without the possible country element is desired.
# Removes USA and variants from place fields
# Call as: [lib.stripUSA:place_fieldname]
[{1}:replace:[, ]+USA\b::i:replace:[, ]+United States.*::i]
As with most Library Templates, the first thing that happens when the Template is executed is that the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable containing the place name. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.
The Template consists of a single Variable with :replace Transforms chained to find either the abbreviation "USA" or the name "United States." First, the Template replaces the "{1}" term with the value from the place Variable:
[{1}:replace:[, ]+USA\b::i:replace:[, ]+United States.*::i]Next, it applies the :replace Transform to search for "USA", with a leading comma and/or space, and if found, replacing that string with nothing:
[{1}:replace:[, ]+USA\b::i:replace:[, ]+United States.*::i]The :replace Transform, in green above, takes three parameters. The first, in yellow above, is the string that is being searched for. In this case it is ", USA". The " [, ] " term tells the Transform to search for a comma or a space, and the " + " following it says it must find at least one of them but there may be more. That is, either or both must precede the "USA" text. The " \b " term tells the Transform that the "USA" text must be at the end of a "word", that is not embedded in a longer word. This combination insures that "USA" will not be found if it occurs within a longer name, and causes a comma and/or space before "USA" will be included in the replace operation.
The second parameter, in pink above, tells the Transform what to replace the string found by the first parameter with. In this case it is empty. The string, if found, will be replaced with nothing. In other words, the text will simply be removed.
The third parameter is normally optional, but must be included here because another Transform is "chained" after the first. It is for flags that control some operations of the Regular Expression. In this case the "i" flag is used, to indicate that the expression should be insensitive to case; that the text may be either upper or lower case letters.
Then a second :replace Transform is used, to test for the string ", United States." It works the same as the first except for the string that is being searched for, and the instead of insuring that the test string is at the end as was the case in the first part, it includes any text after that string:
[{1}:replace:[, ]+USA\b::i:replace:[, ]+United States.*::i]
The term in blue above – " .* " – tells the Transform to search for any characters, zero or more times, and if found include them with the found string. This means in addition to ", United States" the replace function will find ", United States of America" and other variations starting with "United States". While some other countries sometimes include "United States" in their name, that is not a concern since I only use this Template for records from my home country.
If other forms of the country name or abbreviation are found in some records, additional instances of the :replace Transform can be added to remove them as well.
Repositories use a variety of standards in indexing names that begin with "Mc" or "Mac," and are sometimes inconsistent. Often the following letter is not capitalized, even when it is in the original record. There may or may not be a space after "Mc" or "Mac," and with hand-written documents it is often impossible to be sure whether there was one in the original. I have decided to always capitalize the letter following "Mc" and never include a space in my database, no matter how the record is indexed, except when an image of the original record clearly shows otherwise. This Library Template "corrects" index names accordingly.
My Template does not address names beginning with "Mac" because in my data at least, most of the apparently originally "Mac" names seem to have been commonly spelled without a following uppercase letter in the U.S., and I have as many names starting with "Mac..." that were apparently never Mac names, like Machen, Mack, and Macon.
Library, intended for use in a Text Template that has the same Heading as the name of the Variable in the record.
In a Text Template, call the Library Template using the "call" described in the second Comment Line, substituting the actual name of the field containing the place value for "name_fieldname." The Library Template produces no output unless it makes a "correction" and thus does not trigger the User Field styling in the OraPanel indicating a change in the name Variable unless one has actually been made.
# Removes space after Mc in Mc-names, and capitalizes following letter
# Call as: [lib.cleanMc:name_fieldname]
# test for existence of "Mc" in surname followed by space or lower case letter, if so continue, else do nothing
<[?:{1}:nameSurname:/^Mc[ a-z]/ ]
# save post-Mc part as variable [M]
[=:M:[{1}:nameSurname:extract:Mc ?([a-z]+)]]
# Recreate name without space after Mc and [M] capitalized
<[{1}:namePrefix] >[{1}:nameGiven] Mc[M:capitalize]<, [{1}:nameSuffix]>>
As with most Library Templates, the first thing that happens when the Template is executed is that the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable containing the subject's name. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.
The entire Template is enclosed in Conditional brackets. The first element tests for whether the surname begins with "Mc" followed by a space or followed by a lower case letter. This is done with a Value Test Variable that tests for the target condition with the following Template segment:
<[?:{1}:nameSurname:/^Mc[ a-z]/ ]
The Value Test Variable, shown in green, uses the Regular Expression form, as indicted by enclosing the comparand pattern being inclosed in slash characters. It tests for the string "Mc" and a space or lower case letter occurring at the beginning of the surname, which is produced by applying the :nameSurname Transform to the name Variable. The test pattern starts with the "^" character, indicating the search pattern must be found at the beginning of the string, that is the Surname. Next, the characters "Mc" must be found. Finally, the "[ a-z]" term specifies that the next character must be a space or a letter a through z. The Regular Expression form of the Value Test is by default case insensitive, but the space following the closing slash makes the test case sensitive, so there is a match only if the letter following "Mc" is lower case..
If the target sting is not found the Value Test Variable returns "false" and the entire statement is ignored, and the Template produces no output. If the target string is found it returns "true" and remainder of the Conditional statement is evaluated.
If this test is passed, the next segment of the Template extracts the part of the surname following "Mc" (and a space if present) and assigns it to the temporary Variable "M" using this expression:
[=:M:[{1}:nameSurname:extract:Mc ?([a-z]+)]]
This segment uses an Assignment Variable to assign to the temporary Variable "M" that part of the surname that follows "Mc" or "Mc ". That string is found by applying an :extract Transform to the name variable after first applying the :nameSurname Transform to obtain the surname. The :extract Transform, shown in yellow above, uses a Regular Expression to identify the target string. The string is to start with "Mc", optionally followed by a space (the question mark after the space indicates it is optional), then followed by one or more letters a through z. The "[a-z]" term indicates any letter and the following plus sign indicates that one or more letters are to be found. The :extract Transform is by default case insensitive, so either upper or lower case letters may be found. The parentheses indicate that is is only the letters following the "Mc" and space that are to be extracted.
Finally, the Template creates the entire name with any space following "Mc" removed and the term after "Mc" capitalized, with this segment:
<[{1}:namePrefix] >[{1}:nameGiven] Mc[M:capitalize]<, [{1}:nameSuffix]>>
First, the name prefix (e.g. Dr., or Capt.), if any, is output, produced by applying the :namePrefix Transform to the name Variable. This term is enclosed in Conditional brackets so the following space will not be output if there is no prefix. Next the given name is output by applying the :nameGiven Transform to the name Variable.
Next the corrected surname is added by outputting the letters "Mc" followed by the string assigned to the M Variable in a step above, and applying the :capitalize Transform to capitalize the first letter. Finally, any suffix (e.g. Jr., III) is output after a comma and space. Again, Conditional brackets are used so the introductory comma and space are not output if there is no suffix.
Thanks to John W. Nunnally for suggestions that significantly simplified this Template.
This Template is used to cause the text created by a Text Template to appear in red in the OraPanel. I use it for various notices or warnings created with Text Templates, in order to make them more noticeable.

Library, intended for use with in a Text Template.
In a Text Template, call the Library Template using the "call" described in the second Comment Line, substituting the actual name of a field containing the desired text, or the actual text to be used, for "text_or_variable." Place the call statement in the place in the Template where the desired output text is generated.
# Colors text produced by a Text Template red
# Call as: [lib.red text:text_or_variable]
\<span style="color:Red"\>{1}\</span\>
As with most Library Templates, the first thing that happens when the Template is executed is that the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable or text that is to be output as red text. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.The Template creates an HTML <span> tag, then a CSS style to color the output text of the Text Template that calls the Library Template.
The Template first creates the opening and closing elements of a <span> tag using the appropriate HTML codes:
[\<span style="color:Red"\>{1}\</span\>Because the opening and closing angle brackets that are part of the HTML code are also special characters to ORA, the must be preceded by the "escape" character - " \ ".
Next it applies the CSS codes to style the contents of the <span> tag as red text:
[\<span style="color:Red"\>{1}\</span\>Finally, the Template replaces the "{1}" term with the text supplied by the "call" statement in the Text Template:
[\<span style="color:Red"\>{1}\</span\>
The OraPanel is displayed in a web browser, which interprets these codes to display the text in red.
This Template is used to create a distinctive divider between output of Text Templates in the OraPanel and items ORA extracts from the page and any items created by persistent Assignment Variables. It can be placed at the top of Text Template items if they are in the default position, at the bottom of the OraPanel, or at the end of Text Template items if the option to place them at the top of the OraPanel is used. Two of many possible styles are illustrated below.
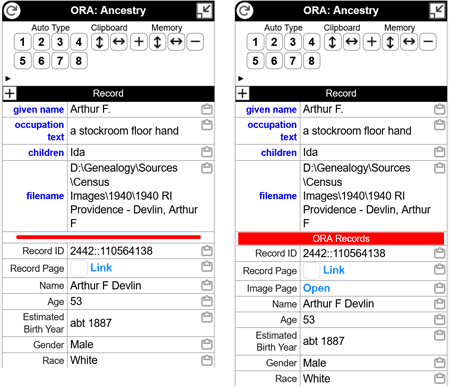
Library, intended for use with in a Text Template.
In a Text Template, call the Library Template using the "call" described in the second Comment Line. The Text Template should be the first one if the divider is to be at the top, or the last one if it is to be at the bottom as shown in the illustrations above. Using an "illegal" character, such as the equal sign, as the header of the Text Template causes the row to have a single cell as shown above.
# creates a divider bar in the Control Panel
# Call as: [lib.divider]
# Use in the first or last Text Template, and enter only an equal sign in the Header field of the Template
#\<div style="background:Red; color:White; text-align:center; font-size:13px;"\>ORA Records\<\div\>
\<hr style='border: 3px solid Red; border-radius: 2px; margin:4px 15px 4px 15px'\>
The Template above creates the divider illustrated on the left above. It uses an HTML <hr> (horizontal rule) tag, then a CSS style to color and size the output.
The opening and closing elements of a <hr> tag are shown in green below:
\<span style='border: 3px solid Red; margin:4px 15px 4px 15px'\>Because the opening and closing angle brackets that are part of the HTML code are also special characters to ORA, the must be preceded by the "escape" character - " \ ".
Next it applies the CSS codes to style horizontal rule with a 3-pixel wide red border, and applies margins at the sides and top and bottom to provide some space around the red line. If you try this method you may want to adjust the size of the border and margins to suit your preferences and your system.
The example on the right above was produced with this Template:
\<div style="background:Red; color:White; text-align:center; font-size:13px;"\>ORA Records\<\div\>It uses a <div> HTML tag, shown in blue above, to enclose the output text "ORA Records," shown in yellow. Again the angle brackets are preceded by the "escape" character - " \ ".
Then it applies the CSS codes to specify the background and text color, center the text, and specify its size. If you try this method you can change the text and colors to fit your preferences.
These are only two of many possible examples of how a divider could be constructed. Feel free to experiment. By using this as a Library Template it is simple to modify the divider's appearance in all collections if you change your mind about which style works best for you.
In some states in the United States there are governmental structures within counties called townships. It is not uncommon for there to be cities or towns with the same name as a township in the same state, often in a different location. So it is important to identify whether the place is a township or a town or city of the same name. Images of original records generally show when a place is in a township, but some Repositories fail to include that information in the indexed place name, especially for census records.
I have included a prompt in my census Templates to ask whether a place is a township, but that prompt was annoying when the place is obviously not a township. This Template identifies locations that are obviously not townships based on key terms in the place name, or because the place is in a state where townships were not used, and only creates a prompt when it cannot determine that the place was not a township..
Library, intended for use with in an Auto Type Template.
In an Auto Type Template, call the Library Template using the "call" described in the second Comment Line, substituting the actual name of a field containing place name for "place_fieldname." For example if the name of the field contains the place is "Residence" use a statement like this:
[lib.checkTwp:Residence]
The Template searches for terms in the place name that indicate that the place was not a township. I have found that if the indexed name of a place includes the words "ward" "district" "precinct" or "city" it is not a township. In some records the field "ward of city" exists, which also indicates the place is not a township. If these key terms are not found the Template examines the state to see whether the place is in a state that never used townships as governmental units.
If the Library Template cannot determine that the place was not a township it will create prompt asking the user "Is a Township". If the user responds with "y" the Library Template creates a field named "Is a Township" with a value "y" in the OraPanel. Then the Template that called the Library Template, or any Template run later, can use that value to control output. For example the following statement will add the text "Twp." after the name of the "city" if the place was a township:
[City]<[?:Is a Township=y] Twp.>
For an example of the use of this Template, see my article on an Example Census Source Template.
# Checks whether a place is a township, asking if necessary
#Call as: [lib.checkTwp:place_fieldname]
# first tests whether township already set, if so exits
<[?:twp set]|
# if not:
# 1. searches for "ward" or "district" or "precinct" in place name
# 2. searches for presence of field [ward of city]
# 3. searches for a state known to not have townships in the place name
# 4. if none sets test to "fail"
<[?:{1}/ward|district|precinct|city/]|[?:Ward of City]
|[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|Kentucky|
Louisiana|Maine|Maryland|Massachusetts|Mississippi|Nevada|New Hampshire|New Mexico|Oregon|
Rhode Island|Tennessee|Texas|Utah|Vermont|Washington|Wyoming/]|[=:test:fail]>
# If test=fail, asks and sets "y" or leaves empty
<[?:test=fail][==:Is a Township]>
# then sets "twp set" to "y"
[==:twp set:y]>
The first thing the Library Template does is to determine whether the question of whether the place is a township has previously been answered by running this Library Template. It does that by testing whether field "twp set" exists in the OraPanel. That field is created as the final step when the Library Template runs, so if it is called again without changing to a different record in the Repository it will not run a second time.
This is done by enclosing the entire Template in an Alternatives Conditional structure, where the first segment is a Value Test Variable to test whether the "twp set" Variable exists, and the second segment is the entire remainder of the Template. The Value Test Variable is shown in green below, and the elements of the Alternatives Conditional are shown in blue below:
<[?:twp set]|
<[?:{1}/ward|district|precinct|city/]|[?:Ward of City]
|[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|Kentucky|
Louisiana|Maine|Maryland|Massachusetts|Mississippi|Nevada|New Hampshire|New Mexico|Oregon|
Rhode Island|Tennessee|Texas|Utah|Vermont|Washington|Wyoming/]|[=:test:fail]>
<[?:test=fail][==:Is a Township]>
[==:twp set:y]>
If the "twp set" Variable is found the first segment of the Alternatives Conditional returns "true," the entire Conditional is satisfied, and the Library Template takes no action and returns control to the calling Template. If the "twp set" Variable is not found, the remainder of the Template comes into play.
As with most Library Templates, when the Template is executed the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable containing the place name. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.
The remainder of the Template consists of three main sections. First, a series of tests tries to determine that the place is not a township. If that fails the second section issues a prompt to ask the user if the place was a township. Finally, the third section creates a field in the OraPanel showing that the question has been addressed, as mentioned above.
The first section, the tests, is part of another Alternatives Conditional structure so that if any of the conditions are found the user is not prompted, otherwise the temporary Variable "test" is set to "fail" so the second section of the Template can prompt the user.
The test section makes three separate tests. The first, shown in green below, tests for the presence of the key words "ward" "district" "precinct" or "city" in the place name using the Regular Expression form of the Value Test Variable, as shown in green below:
<[?:{1}/ward|district|precinct|city/]|[?:Ward of City]First, the Template replaces the "{1}" term with the value from the place Variable:
[?:{1}/ward|district|precinct|city/]Next, it uses the Regular Expression shown in yellow above to test for any of the key words "ward" "district" "precinct" or "city." In this case the expression for the string to be found are the text "ward" "district" "precinct" or "city". They are separated by the vertical bar to indicate that any one of them can be the search target.
If any of the four key words are found, the Value Test Variable returns a value of "true" the Alternatives Conditional, show in blue below, and the Template skips to the second section.
<[?:{1}/ward|district|precinct|city/]|[?:Ward of City]The second test determines whether the Variable "Ward of City" exists. That test, which is simply a Value Test Variable, is shown in green below:
<[?:{1}/ward|district|precinct|city/]|[?:Ward of City]
|[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|
Kentucky|
Louisiana|Maine|Maryland|Massachusetts|Mississippi|Nevada|New Hampshire|
New
Mexico|Oregon|Rhode Island|Tennessee|Texas|Utah|Vermont|Washington|Wyoming/]|
[=:test:fail]>
If that Variable is found, the Value Test Variable returns a value of "true" the Alternatives Conditional, show in blue above, and the Template skips to the second section.
If neither of these tests return "true" then the Alternatives Conditional moves on to evaluate the third segment of that Conditional, the test for state.
The second segment uses a :split Transform to find the name of the state within the place name:
[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|The :split Transform requires two parameters. The first specifies the separator character between elements, in this case a comma, as shown in yellow above. The second tells which segment to capture. In this case it is set to "-1" indicating that the first segment, counting from the end, is to be captured, because the state will be the last element in the place name (the country already having been removed in the calling Template by use of the stripUSA Library Template).
Next the Template tests for a match between the state and the list of states in the Regular Expression shown in blue below:
[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|If the state is found in the list the Value Test Variable, shown below in pink, returns "true":
[?:{1}:split:,:-1/Alaska|Arizona|Colorado|Delaware|Florida|Georgia|Hawaii|Idaho|
Kentucky|Louisiana|Maine|Maryland|Massachusetts|Mississippi|Nevada|New Hampshire|
New Mexico|Oregon|Rhode Island|Tennessee|Texas|Utah|Vermont|Washington|Wyoming/]
If this segment of the Alternatives Conditional returns "true" the Template skips to the second section. If not, the fourth segment of the Conditional creates the temporary Variable "test" and assigns it the value "fail" with an Assignment Variable, as shown below:
[=:test:fail]
The Template now moves on to the second section, which uses a Value Test Variable to test whether the Variable "test" has been set to "fail'. If so, a persistent Assignment Variable is used to prompt the user with the question "Is a Township"? If not nothing happens and the Template moves on to the third section. The entire third section of the Template is shown below:
# If test=fail, asks and sets "y" or leaves empty
<[?:test=fail][==:Is a Township]>
If the prompt is issued, the user should enter "y" if the place is a township. If its not, the user can enter anything else, or simply press Enter without entering anything. If the user enters any value the "Is a Township" field is created in the OraPanel and can be used this the calling Template or any other Template to control output. In any case, the final section then creates the field "twp set" with an Assignment Variable, as shown below:
[==:twp set:y]
This is used, as described in the beginning of this "How it Works" section, to keep the Library Template from being run unnecessarily a second time.
Place names, particularly census records, often include terms that are not towns or cities, or include terms that describe parts of cities, like wards. Such names properly describe the place for record purposes, and may be included in citations, but may not be helpful in narratives that are describing were people were located. This Library Template is intended to strip such place names to terms that describe places in terms understandable today, or example in census event records.
Library, intended for use with in a Text or Auto Type Template.
In a Text or Auto Type Template, call the Library Template using the "call" described in the last Comment Line, substituting the actual name of the field containing the place value for "place_fieldname." Place the call statement in the place in the Template where output of the modified place name is desired.
For an example of the use of this Template, see my article on an Example Census Event Template.
# Leaves City empty if only two parts to place field
# Leaves City empty if city contains "precinct"
# Extracts City & removes Ward & District details info
# Expects City to be in first split, comma delimited
#Call as: [lib.cleanCity:place_fieldname]
<[?:{1}:splitCount:,=2]|[{1}:split:,:1:replace: ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]>
As with most Library Templates, the first thing that happens when the Template is executed is that the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable containing the place name. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.
The Template is enclosed in a two-part Alternatives Conditional. The first part of the Conditional uses a Value Test Variable and :splitCount Transform to determine whether the place name consists of only two parts (assumed to be county and state).
First, the Template replaces the first " {1} " term with the value from the place Variable:
<[?:{1}:splitCount:,=2]|[{1}:split:,:1:replace: ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]>Next, it applies the :splitCount Transform to test whether the place name, when split into parts, has two parts:
{1}:splitCount:,The :splitCount Transform, in green above, takes one parameter, the character that separates the parts, shown in yellow above. in this case the separator is a comma. The Transform returns the number of parts found. Then the Value Test Variable determines whether that count was two:
[?:{1}:splitCount:,=2]
This Value Test Variable consists of the question mark and colon, shown in green above, an expression that creates the value to be tested, in this case the field and :splitCount Transform, and the test to be made, in this case " =2 " as shown in yellow. If the place does have two parts the Value Test returns "true" and the Conditional is satisfied. The rest of the Conditional is ignored, and no output is produced. the "city" is left empty.
If there are more than two parts, the rest of the Conditional comes into play. It then replaces the second " {1} " term with the value from the place Variable, and a series of Transforms, chained together, are applied. The first is a :split Transform, to extract the "city" part of the place name:
[{1}:spit:,:1:i:replace ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]
The :split Transform has three parameters here. The first, in yellow above, is a comma indicating that the separator of the parts is a comma. The second, in pink, is a one, indicating that the first part, the city name, is to be used. The third parameter is normally optional, but must be included here because another Transform is "chained" after the first. It is for flags that control some operations of the Regular Expression. In this case the "i" flag is used, to indicate that the expression should be insensitive to case; that the text may be either upper or lower case letters.
Next a :replace Transform is used, to remove the string "ward" together with any associated text:
[{1}:split:,:1:replace: ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]
The next :replace Transform, in green above, uses a Regular Expression, in yellow, to define the string that is to be replaced. The expression starts with a space and the text "ward" indicating that the string must include that text with a leading space. Next is a period and an asterisk. The period term represents any character, and the asterisk means there may be zero or more of them. The term ward in a place name generally includes a number or some other label. This term is intended to include those characters in the searched for string.
The second parameter, in pink is empty, telling the Transform to replace the found string with nothing. Thus the "ward" and its leading space and any following text, are removed from the "city" name.
Next a second :replace Transform is used, to remove the string "district" together with any associated text:
[{1}:split:,:1:replace: ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]
It works the same as the :replace Transform for "ward" except for the question mark after the leading space. This means the string searched for may include a space, but the question mark indicates that if there is no space before the next text that can be ignored. This string too, if found, is replaced with nothing by the empty second parameter in pink. Thus the "district" and its associated leading space, if any, and any following text, are removed from the "city" name. If there is nothing preceding the term "district" in the "city" name it will now be empty.
Finally a third :replace Transform is used, to remove the string "precinct" together with any associated text:
[{1}:split:,:1:replace: ward.*::i:replace: ?district.*::i:replace:.*precinct.*:]
It works the same as the :replace Transform for "district" except that it begins with a period and asterisk. This means that any number of characters before the text "precinct" will be included in the string being searched for. This string too, if found, is replaced with nothing by the empty second parameter in pink. Thus if the text "precinct" is found, the "city" name it will now be empty. Since this is the last Transform in the chain, the optional third parameter is not required.
I prefer to have the suffix of road or street names – "Street" or "Avenue" for example – entered in my database in a consistent style. My preferred style is to use my standard abbreviations for the more common suffixes. For example, I use "St." and "Ave." instead of spelling out those terms. This Template examines the street name as found in the record index and if they appear different than my preferred style, changes them to the way I like them.
Library, intended for use with in a Text or Auto Type Template.
In a Text or Auto Type Template, call the Library Template using the "call" described in the second Comment Line, substituting the actual name of the field containing the place value for "place_fieldname." Place the call statement in the place in the Template where output of the place name without the possible country element is desired.
For an example of the use of this Template, see my article on an Example Census Event Template.
# Replaces Street, Avenue or Road with abbreviation; adds period if missing
#Call as: [lib.cleanStreet:street_fieldname]
[{1}:replace:\bstreet:St.:i:replace:\bst$:St.:i:replace:avenue:Ave.:i
:replace:\bave$:Ave.:i:replace:road:Rd.:i:replace:\brd$:Rd.:i]
As with most Library Templates, the first thing that happens when the Template is executed is that the parameter references are replaced by the parameters in the call statement. In this case, there is one parameter, the Variable containing the place name. So each occurrence of the term "{1}" in the Template is replaced with the value of that Variable.
The Template consists of a single Variable with a series of :replace Transforms chained to find either the terms "Street", "Avenue" or "Road", or their shortened forms without trailing periods, and replace them with my standard abbreviations for those terms.
First, the Template replaces the "{1}" term with the value from the place Variable:
[{1}:replace:\bstreet:St.:i:replace:\bst$:St.:i:replace:avenue:Ave.:iNext, it applies the first :replace Transform to search for "street" at the beginning of a "word" and replace it with "St.":
:replace:\bStreet:St.:iThe :replace Transform, in green above, takes three parameters. The first, in yellow above, is the string that is being searched for. In this case it is "street". The " \b " term in front tells the Regular Expression that the text "street" must be at the beginning of a "word" and not embedded as part of a longer word.
The second parameter, in pink above, tells the Transform what to replace the string found by the first parameter with. In this case it is the text "St."
The third parameter is normally optional, but must be included here because another Transform is "chained" after the first. It is for flags that control some operations of the Regular Expression. In this case the "i" flag is used, to indicate that the expression should be insensitive to case; that the text searched for may be either upper or lower case letters.
Then a second :replace Transform is used to find the string "st" if it exists and replace it with "St." with a period.
:replace:\bstreet:St.:i:replace:\bst$:St.:i]
It works the same as the first :replace Transform except that the search term includes the " $ " at the end, meaning that the text "st" must be at the end of the string. Thus the text "St." with a period would not be replaced.
The remaining terms of the Template are pairs of :replace Transforms that work in the same way searching for and replacing the suffixes "Avenue" and "Road" and their period-free abbreviations.
Creates Variables for subject and possessive pronouns and populates them with male, female, or plural pronouns based on fields in an Ancestry census record. The Variables are intended for use in a Template that produces narrative text for the the Memo of a Tag recording information from the census record.
Library, intended for use with in a Text or Auto Type Template.
In a Text or Auto Type Template, call the Library Template using the "call" described in the last Comment Line. No reference to field values is needed, as the Template uses the field names used in applicable census collections.
The Template creates the Variable [He-She] and populates it with "they" for married subjects, and "he" or "she" for unmarried subjects depending on the value in gender field. It also creates the Variable [His-Her] and similarly populates it with "their", "his" or "her".
The Variables created may then be used in the calling Template to create the desired output text. The call statement for the Library Template must be placed earlier in the calling Template than the point where the Variables are used.
For an example of the use of this Template, see my article on an Example Census Event Template.
# Creates the variables [He-She] and [His-Her] and populates them with
# "they" "he" or "she" and "their" "his" or "her" respectively.
# Those variables can then be used in the Templates.
# Designed for Ancestry US Census records for 1900 through 1950.
# Depends on the fields [Marital Status] and [Gender] being correctly indexed.
# call as: [lib.CensusHe-She]
<[?:Marital Status=Married][=:He-She:they]|[?:Gender=Female][=:He-She:she]|[=:He-She:he]>
<[?:Marital Status=Married][=:His-Her:their]|[?:Gender=Female][=:His-Her:her]|[=:His-Her:his]>
The Template consists of two separate three-part Alternative Conditionals, each generating one of the two Variables. The first Conditional creates the Variable [He-She] with a series of pairs of Value Test Variables and Assignment Variables. The first part tests whether the subject person is shown as married, and if so assigns the value "they" to the Variable:
[?:Marital Status=Married][=:He-She:they]
The Value Test Variable in green above tests whether the value in Marital Status field is equal to "Married". If it is, that Variable returns "true" and the Assignment Variable in yellow assigns the value "they" to the Variable [He-She]. If the Value Test Variable returns "true" the Conditional is satisfied, there rest of it is ignored, and the Template moves on to the second three-part Conditional.
If the first Value Test Variable does not return "true" the second part of the Conditional comes into play. It tests whether the subject person is shown as female::
[?:Gender=Female][=:He-She:she]
As with the first part, if the Value Test Variable returns "true" the Assignment Variable assigns the text "she" to the Variable [He-She], and the Conditional is satisfied. If it does not, the third part of the Conditional uses an Assignment Variable to assign the text "he" to the Variable [He-She], and the Template moves to the second Conditional. It works the same as the first except the values of "their" "her" and "his" are assigned to the Variable [His-Her].
| ReigelRidge Home | Terry's Tips Home | Contact Terry |
Copyright 2000- by Terry Reigel