 his method is uses so that if no change is made to the name, the User Field Styles indicating a change to the Name value in the OraPanel will not be applied.
his method is uses so that if no change is made to the name, the User Field Styles indicating a change to the Name value in the OraPanel will not be applied.This page created 25 Apr 2023
This article describes some of my example Templates for Online Repository Assistant (ORA). The other example Templates can be found in the index of Example Templates. Other articles in my ORA Section cover various topics about using the software. The "How it Works" section below includes links to articles describing the ORA features used in these Templates.
My approach to using ORA with census records is in three parts:
The Templates were designed for my method of recording census records, which is described more completely in my article on Using ORA with Census Records.
The Templates described in this article are designed to assist in recording data from U.S. Census records for the years 1850 through 1950 on Ancestry.com, in various Tags in The Master Genealogist (TMG). They would likely have to be modified for use with census records for other countries, or for other genealogy programs.
Templates Included in this Article |
|
| Makes the given name easy to copy and paste, standardizing periods after initials | |
| Adds "abt" to indexed birth date fields computed from age when omitted | |
| Removes the country term from the residence field | |
| Corrects misindexed surnames for all members of a household | |
| Creates a list of children of the head of household | |
| Creates a statement of the occupation, and industry when present | |
| Types data on hours worked, etc., from 1940 and 1950 censuses in Memo field | |
| Creates a filename to be used when saving an image of the census document. This Template is described in a my Template Example – Filename article | |
For each Template there is a description of why it is used and what it does, notes on how to use it, and text of the Template itself. That is followed by a detailed description of how it works so that readers can understand how to modify it if desired or how to apply the techniques in other applications.
When entering a new person, or when a census entry provides the name in a form not previously seen (e.g. when it provides the formal name when previous sources showed only nicknames) it is handy to have the given name listed in the OraPanel to copy into a Name tag. The Template also adds periods after initials if they are missing in the name as indexed. I use this Template for every census year Collection.
Text Template.
When it is desired to use the given name as shown in this census, click the "clipboard" icon next to it in the OraPanel to copy it to the Windows clipboard and paste it into the desired field in the genealogy program
[Name:nameGiven:replace:\b([a-z](?!\.))\b:$1.]
The Template extracts the given name with the :nameGiven Transform, then uses the :replace Transform to search for an initial without a following period, and if found adds the period.
[:replace:\b([a-z](?!\.))\b:$1.The first parameter of a :replace Transform defines the string to be replaced, if found. The term in yellow above searches for any letter between a and z (case insensitive). The term in green above is called a "negative lookahead" searching for a period, which means it matches only if the period does not exist. The characters in pink indicate a word boundary, so the terms between them will be found only if they are the entire "word." In other words, a single letter by itself, not part of a longer name. The yellow and green terms are enclosed in parentheses, forming a "capture group" that can be used in the second parameter of the :replace Transform.
The second parameter defines what to replace the target string with. That parameter is shown in blue above. In this case it specifies that the string found, a single letter without a following period, is to be replaced by the first "capture group," indicated by the $1 term, and a period. Since the first capture group was the letter found, it is replaced by itself, followed by a period.
If the target string is not found, if there is no single letter not followed by a period, the :replace Transform does nothing and the Template outputs the given name unchanged.
Ancestry.com, and perhaps other repositories, often compute an estimated birth year when only a person's age is recorded in the source document. Ancestry generally prefixes the computed birth year with "abt" but does not in a few census years. For those years I include this Template to correct the data displayed in the OraPanel, so it is correct when used by other Templates.
Text Template.
The Template examines the Birth Date Variable extracted by ORA from the page to see if it includes the string "abt" and if not adds that string to the field so when the field is copied or used in other Templates it will include that text.
# Check for missing "abt" in Birth Date field and add it if missing.
<[?:Birth Date/^abt/]|[==:Birth Date:[Birth Date:prepend:abt ]]>
The Template first tests for whether the birth date begins with "abt". This is done by placing a Value Test Variable that tests for the target string and as the first term of an Alternative Conditional. If it is not found the second term of the Conditional uses an Assignment Variable to add the desired string. This is done with the following Template segment:
<[?:Birth Date/^abt/]|[==:Birth Date:[Birth Date:prepend:abt ]]>
The characters forming Alternative Conditionals are shown in pink above. The Value Test Variable, shown in green above, uses the Regular Expression form, as indicted by enclosing the comparand pattern in slash characters. It tests for the string "abt" at the beginning of the value (the "^" character means the target text must be at the beginning of the string). If the sting is found the Value Test Variable returns "true" the conditional is satisfied, and the Template produces no output.
If that string is not found the first segment of the Alternatives Conditional returns "false" and the second segment comes into play. In it the persistent Assignment Variable, shown in yellow above, assigns a new value to the Birth Date Variable. That value outputs the current value of the Birth Date field, and uses the :prepend Transform to add the text "abt" and a space before that value.
Ancestry.com generally omits the country when indexing the Residence field, but in some years includes it, as "USA." Rather than deal with that inconsistency in my other census Templates, I use this Template in those years where that term is included to remove it.
Text Template.
The Template examines the Residence Variable extracted by ORA from the page to see if it includes the string ", USA" and if found removes so the field can be used in other Templates that are the same as those used in other census years.
[Residence:replace:, USA::l]
The Template uses a :replace Transform to search for the string ", USA in the Residence field, and if found, replace it with nothing. The "l" (lowercase letter L) flag is used to indicate that the Transform is to operate in literal, as opposed to Regular Expression, mode.
This set of three Templates is used to correct misindexed surnames in collections of related records, like a census entry recording members of a household in linked records. Ancestry.com, and other repositories, sometimes include alternate variations of names but depending on how those variations are entered, ORA may not find the "correct" one (in my view the "correct" one is the one that agrees with how I read the image of the original document, not necessarily the variation actually used by the person).
Misindexed names, or other values, for a single record can easily be fixed in ORA by holding the Alt key while clicking the field containing the incorrect value. Make the correction in the dialog box that opens and it will be used by any Template that refers to that field. But for groups of records, like a census record for a household, a correction to the family's surname made that way is lost when one moves to the record of another person in the household. It is easy to forget to repeat the correction for the new person. This set of Templates makes a correction that is retained when focus is moved to other people with the same misindexed surname.
This Template as shown automatically "corrects" mis-formed "Mc" names, but including that feature is optional.
Set of three Text Templates.
A Text Template, the second one described below, searches for a specific misspelled surname, and if found changes the name Variable to use the corrected spelling. When a new misindexed surname is found, the OraSettings screen must be opened, and the incorrect and correct spellings entered in the Template. While this is less convenient than simply correcting the spelling by clicking the field while holding the Alt key, this method automatically applies the correction to other members of the household when focus is change to them, while the simpler method does not.
If the "Mc" name feature is included those names are automatically corrected if needed, as explained below.
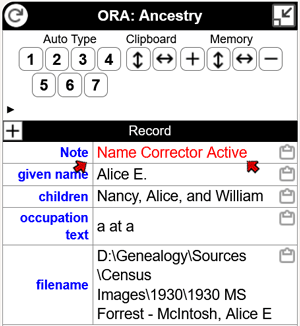
Only that one Template is strictly required, but there is the potential that the "correction" could be misapplied to another record later. To guard against that issue the other two Templates automatically produce a highly visible notice in the OraPanel when a correction is being applied.
First Template, heading: var.name
# saves name as indexed to compare for possible change
[Name]
Second Template, heading: Name
# changes wrong spelling in indexed name
# enter wrong spelling in first parameter and correct spelling in the second
[=N:[Name:replace:Cabe:Cobb]]
<[?:N=[Name]]|[N]>
# fix Mc Name if applicable
[lib.cleanMc:Name]
Third Template, heading: Note:
# tests whether name was changed and if so produces note in OP
<[?:var.name=[Name]]|[lib.red text:Name Corrector Active]>
The first Template simply saves the original spelling of the name as indexed, for use in the third Template to determine whether a note about a change should be produced. The "var." prefix to the heading means the Variable created is not to appear in the OraPanel. The Variable [Name] is used to "output" the original value of the name to the hidden var.-Variable. This Template is not needed if you choose to omit the name-change notice.
The second Template is the heart of the method. In it, a :replace Transform is used search for the misspelled version of the surname, and if found replace it with the corrected spelling. In use, both these values must be manually entered in the Template for each new misindexed surname encountered. The Template starts with an Assignment Variable that assigns the corrected spelling to the temporary Variable "N" if the misspelled version is found:
[=N:[Name:replace:Cabe:Cobb]]The corrected spelling is created by the :replace Transform, shown in green above. The first parameter, shown in yellow above, is the string that is being searched for, the incorrect spelling of the surname. The second parameter, shown in blue above, is the string that is to replace the incorrect spelling. Both of these parameters must be manually entered for each new misspelled surname encountered. If the misspelled text is not found, the temporary Variable "N" will contain the same value as the original Variable Name.
The next term of this Template tests to see whether the value of the temporary Variable N is the same as the value of Name, and if not outputs the value of N:
<[?:N=[Name]]|[N]>The Value Test Variable, shown in green above, is enclosed in an Alternatives Conditional structure, shown in pink above. If the value of the temporary Variable N is the same as the value of the Name Variable, the Value Test Variable returns "true," the Conditional is satisfied, and no output results. If the values are not equal, the second segment of the Conditional comes into play, and the value of the N is output.
This method is uses so that if no change is made to the name, the User Field Styles indicating a change to the Name value in the OraPanel will not be applied.
The final term of this Template applies my Library Template to automatically standardize display of names beginning with "Mc." This Template is described in my Library Template Examples article. It's use in this Template is entirely optional, and it can be omitted if automatic "correction" of Mc names is not desired.
The third Template in this set creates a prominent notice in the OraPanel, as shown on the right, when the surname has been changed by the Template above. It and the first Template in this set can be omitted if the notice is not desired.
This Template tests whether the original value for the Name Variable, which is stored in the Variable var.name by the first Template of this set, with the value of the Name Variable after any changes made by the second Template of the set. If they are different a message "Name Corrector Active" is displayed in the OraPanel.
The Template uses a Value Test Variable, shown in green below, enclosed in an Alternative Conditional structure, to determine whether the value of the Name field has been changed, with the following expression:
<[?:var.name=[Name]]|[lib.red text:Name Corrector Active]>
If the two values are the same the Value Test Variable returns "true," the Conditional is satisfied, and no output results. If the values are not equal, the second segment of the Conditional comes into play, displaying the notice. The notice could be just the text but I have used my red text Library Template, described in my Library Template Examples article, to make the notice more visible.
For people on the fringes of my research interests, for example parents of the spouse of a distant cousin, I often do not record in my database any of their children other than the ones of direct interest. When I record census records with such people as head of household, I record the names of their children only in the Memo field of the Census Tag. The Templates described here attempt to create a list of first names of the children in the household to be copied and pasted into the Tag Memo. Because of the various household configurations and variations in how they are indexed, the list may include others and thus may require manual editing after pasting it in the Memo field.
This is a set of two Templates. The first extracts the first names of all the children, and the second organizes the list for display with the word "and" between the last two. Two versions of the first Template are provided. One is for year when Ancestry.com has provided a separate field for "inferred children" and the other is for other years when only a list of all household members is provided. Using the "inferred children" list helps to exclude members of the household who are not children of the head of household.
Set of two Text Templates.
When it is desired to use the list of children as shown in this census, set the focus to the Head of Household. Then click the "clipboard" icon next to the "children" field in the OraPanel to copy the list to the Windows clipboard, and paste it into the desired field in the genealogy program. Examine the list to see if anyone other than the children are included, and edit as needed. If some of the children are entered in the Tag as Witnesses, I edit them out of the pasted list in the Memo field.
First Template, version for census years that do not include "Inferred Child" Variable. Heading: var.children
<[?:Spouse's Name]|[Household Members:split:,:2:split: :1], >
<[Household Members:split:,:3:split: :1]>
<, [Household Members:split:,:4:split: :1]>
<, [Household Members:split:,:5:split: :1]>
<, [Household Members:split:,:6:split: :1]>
<, [Household Members:split:,:7:split: :1]>
<, [Household Members:split:,:8:split: :1]>
<, [Household Members:split:,:9:split: :1]>
<, [Household Members:split:,:10:split: :1]>
<, [Household Members:split:,:11:split: :1]>
<, [Household Members:split:,:12:split: :1]
First Template, version for census years that do include "Inferred Child" Variable, currently 1850-1870. Heading: var.children
[Inferred Child:split:,:1:split: :1]
<, [Inferred Child:split:,:2:split: :1]>
<, [Inferred Child:split:,:3:split: :1]>
<, [Inferred Child:split:,:4:split: :1]>
<, [Inferred Child:split:,:5:split: :1]>
<, [Inferred Child:split:,:6:split: :1]>
<, [Inferred Child:split:,:7:split: :1]>
<, [Inferred Child:split:,:8:split: :1]>
<, [Inferred Child:split:,:9:split: :1]>
<, [Inferred Child:split:,:10:split: :1]>
<, [Inferred Child:split:,:11:split: :1]>
<, [Inferred Child:split:,:12:split: :1]>
Note that for 1870 "Inferred Child" field is called "Inferred Children" and the Variable names above have to be adjusted accordingly.
Second Template, Heading: children
[=:count:[var.children:splitCount:,]]
<[?:count=2][var.children:replace:,: and]|[var.children:replace:, ([^,]*$):, and $1]>
The "var." prefix to the heading of the first Template means the Variable created is not to appear in the OraPanel. The first version of that Template, intended for years when no list of "inferred children" is provided, extracts first names from the Household Members list. Since the first person listed will be the head of household, the Template starts with the second person, and tries to determine whether that is the spouse of the head of household by using a Value Test Variable to see whether there is a Variable "Spouse's Name" as shown in green below:
<[?:Spouse's Name]|[Household Members:split:,:2:split: :1], >
The entire segment is enclosed in an Alternatives Conditional structure so that if "Spouse's Name" Variable is found Value Test Variable returns "true," the conditional is satisfied, and the second term is ignored. If the Variable is not found, the second person is assumed to be a child and the second segment of the Conditional extracts that person's first name.
The first name is extracted with a pair of :split Transforms applied to the Variable "Household Members", as shown below:
[Household Members:split:,:2:split: :1]
The names and the list are separated by commas, so the first :split Transform, shown in yellow above, splits the value in the Variable at commas, and selects the second split in order to find the second person. Than the second :split Transform, shown in blue above, splits that result at spaces, choosing the first in order to find the first name.
All the remaining segments in the Template use the same method, changing the second parameter of the first :split Transform, to extract the remaining names on the list. Each is enclosed in Conditional brackets with its comma and space, so segments searching for names that do not exist do not produce extra commas and spaces.
The second version of the first Template, intended for years where there is a list of "inferred children" extract the names, separated by commas and spaces, in the same way. Since the spouse, if present, is not included in these lists, the term testing for Spouse's Name is not required.
The second Template in this set simply searches for the last name, with its preceding comma and space, on the list which has been stored in the Variable "var.children" by the first Transform, and replaces it with the same name but preceded by the string ", and ". The comma is omitted if there are only two names on the list. It begins by counting the names on the list in order to know whether there are only two, in order to apply the special processing for that case. The names are counted with the :splitCount Transform and the number of names is assigned to the temporary Variable "count" by an Assignment Variable, with this segment:
[=:count:[var.children:splitCount:,]]The :splitCount Transform, in yellow above, is applied to the Variable "var.children," splitting the list at each comma and counting the number of segments found. That count is then assigned as the value of the "count" Variable by the Assignment Variable, in green above.
Next, two terms in a Conditional Variable structure output the list contained in the Variable "var.childen" after replacing the last comma in the list with either the string "and" or the string ", and" depending on whether there are two or more than two names. That is done with this Template fragment:
<[?:count=2][var.children:replace:,: and]|[var.children:replace:, ([^,]*$):, and $1]>In the first segment of the Alternatives Conditional, a Value Test Variable, in green above, tests the temporary Variable "count" to see whether there were two names on the list. If there were, the second term in that segment uses :replace Transform, in blue above, the comma after the first name with a space and the string "and", completing the Conditional and terminating the Template.
If the value of "count" is not 2, the second segment of the Alternatives Conditional comes into play. In it, a :replace Transform searches for the last name on the list with this segment:
[var.children:replace:, ([^,]*$):, and $1]The :replace Transform, in green above, takes two parameters. The first defines a string to be replaced, and the second defines what it is to be replaced with. In this case the string to be replaced is defined in two parts. The first is a comma followed by a space, as shown in yellow above. The second, shown in blue above consists of any character not a comma, specified by the [^,] element, to be repeated any number of times as specified by the "*" character, all to be at the end of the string as specified by the "$" character. Thus the string to be replaced is the last comma, space, and following name.
The blue part of the expression is enclosed in parentheses to form a "capture group" that can be used by the second parameter of the :replace Transform. In this case the capture group will be the last name on the list.
The second parameter, in pink above, specifies that the text defined in the first parameter is to be replaced by the string ", and " and the contents of the capture group, the last name on the list, as specified by the "$1" characters.
If there is only one name on the list no comma will be found, and just that name will be output.
All U.S. censuses from 1850 onward recorded the occupations of adults working outside the home. From 1910 onward the industry of the worker was also recorded. The Templates in this section attempt to extract that information from the fields collected by ORA and format them into a narrative fragment that can be pasted into the Memo field of the Occupation Tag or similar field.
Two versions are provided, one for the years in which only occupations were recorded, and a second for years that also recorded the industry.
The Templates prefix the occupation text with "a" or "an" if its first letter is a vowel, and a space. When the industry is recorded, it is connected with "at" and prefixed with "a" or "an" as appropriate. This often produces useful results, but because of the various ways in which enumerators recorded this information, the result will sometimes require editing to create an acceptable narrative.
Text Templates.
When it is desired to paste the occupation text in the Memo of an Occupation Tag, click the "clipboard" icon next to it in the OraPanel to copy it to the Windows clipboard and paste it into the desired field in the genealogy program
For some years Ancestry.com has not indexed the industry data. In those cases I enter the citation to the census first, because my occupation citation Template for those years, as described in my Example Census Citation Templates article, prompts for the missing information. Once entered for that Template the information is available for this Template.
Template for years in which the industry was not recorded:
<<[?:Occupation/^[aeiou]/]an|a> [Occupation:lowercase]>
Template for years in which the industry was recorded:
<<[?:Occupation/^[aeiou]/]an|a> [Occupation:lowercase]>> < at <[?:Industry/^[aeiou]/]an|a> [Industry:lowerCase]>
The part of the Template that produces the occupation text uses a Value Test Variable within an Alternatives Conditional structure to determine whether the occupation begins with a vowel, as shown in green below:
<[?:Occupation/^[aeiou]/]an|a> [Occupation:lowercase]>The Value Test is in the Regular Expression mode, as indicated by the "/" characters enclosing the target pattern, which is in yellow above. The pattern is looking for any of the letters a, e, i, o, or u, as indicted by the expression "[aeiou]", when located at the beginning of the string, as indicated by the "^" character. If any of those letters is found at the beginning of the string, the Value Test Variable returns "true" and the text "an" which is also in the first segment of the Conditional is output. If those letters are not found the Value Test returns "false" and the second segment of the Conditional comes into play, outputting the text "a".
Next a space is output, followed by the values of the Occupation Variable. That text is changed to lower case if it includes any capital letters by the :lowercase Transform. This usually produces good results, but when parts of the occupation should be capitalized the result must be edited after it is pasted into the field in the genealogy program.
The entire Template expression is enclosed in Conditional brackets so that there is no output when no occupation was recorded.
The Template for years when the industry was recorded works similarly.
The 1940 U.S. census recorded the hours a person had worked in the a recent week, and the earnings in the prior year. The Template assembles that data into narrative form and types it into the Memo field of the Occupation Tag or similar field.
The 1950 census recorded even more detail on hours and earnings, but some of it only for a sample of individuals. Because this data has been fully indexed for only some states I have not yet adequately tested this Template for that year, so it is not included here.
For 1940:
For 1950: Not yet tested.
Auto Type Template.
Open the census Tag or other location where the data is to be typed, place the cursor at the location in the appropriate field, and click the Auto Type button on the OraPanel for this Template. Some additional editing may be required to produce satisfactory narrative text
For 1940:
reporting in 1940 <[?:Gender=Male]he|she> had worked [Hours Worked Week Prior to Census] hours the last week of March, and [Weeks Worked in 1939] weeks the prior year, earning $[Income:replace:([0-9]{1,3})([0-9]{3}):$1,$2]
The Template first outputs the text "reporting in 1940" and a space then uses a Value Test Variable within an Alternatives Conditional structure to produce the pronoun "he" or "she", depending on the recorded gender of the person, with this Template fragment:
reporting in 1940 <[?:Gender=Male]he|she>
Next it outputs the text " had worked ", the value of the Variable "Hours Worked Week Prior to Census", the text " hours the last week of March, and ", the value of the Variable "Weeks Worked in 1939", and the text " weeks the prior year".
Next it outputs the text ", earning $" and the value of the Variable "Income". The value of the "Income" Variable is formatted with a comma after the thousands digit if the number is larger than 999 by using a :replace Transform, with the following Template fragment:
, earning $[Income:replace:([0-9]{1,3})([0-9]{3}):$1,$2]The :replace Transform searches for a group of one to three digits, in green above, followed by a group of three digits, in yellow above. The characters searched for are specified by the "[0-9]" terms. The number of digits is specified by the "{1,3}" and "{3}" terms. Each group is enclosed in parentheses to form a "capture group" to be used by the second parameter of the :replace Transform.
The two strings, one of one to three digits and the second of three digits, if both are found, are replaced by the second parameter, in blue above. The "$1" term specifies that the first capture group, one to three digits, is to be output. Then a comma is output, followed the second capture group, the final three digits. This construction does not deal correctly with numbers over 1,000,000.
| ReigelRidge Home | Terry's Tips Home | Contact Terry |
Copyright 2000- by Terry Reigel